






























 Arguments
Arguments





















The Consensus Project self-rating data now available
Posted on 8 July 2013 by John Cook
I've just uploaded the ratings provided by the scientists who rated their own climate papers, published in our peer-reviewed paper "Quantifying the consensus on anthropogenic global warming in the scientific literature". This is an opportunity to highlight one of the most important aspects of our paper. Critics of our paper have pointed to a blog post that asked 7 scientists to rate their own papers. We'd already done that, except rather than cherry pick a handful of scientists known to hold contrarian views, we blanket emailed over 8,500 scientists. This resulted in 1,200 scientists rating the level of endorsement of their own climate papers, with 2,142 papers receiving a self-rating.
While our analysis of abstracts found 97.1% consensus among abstracts stating a position on anthropogenic global warming (AGW), the method of self-rating complete papers independently found 97.2% consensus among papers self-rated as stating a position on AGW. This independent confirmation demonstrates how robust the scientific consensus is. Whether it's Naomi Oreskes' original analysis of climate research in 2004, Doran and Kendall-Zimmerman (2009) surveying the community of Earth scientists, Anderegg et al. (2010) analysing public declarations on climate change, or our own independent methods, the overwhelming consensus consistently appears.
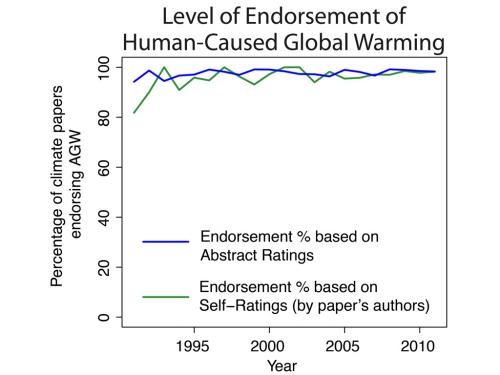
Figure 1: Percentage of climate papers stating a position on AGW that endorse human-caused global warming. Year is the year of publication.
Comparing Abstract Ratings to Self-Ratings
That's not to say our ratings of abstracts exactly matched the self-ratings by the papers' authors. On the contrary, the two sets measure different things and not only are differences expected, they're instructive. Abstract ratings measure the level of endorsement of AGW in just the abstract text - the summary paragraph at the start of each paper. Self-ratings, on the other hand, serve as a proxy for the level of endorsement in the full paper. Consequently, differences between the two sets of ratings are expected and contain additional information.
The abstracts should be less likely to express a position on AGW compared to the full paper - why expend the precious real estate of an abstract on a settled fact? Few papers on geography bother to mention in the abstract that the Earth is round. Among papers for which an author's rating was available, most of the papers that we rated as expressing "no position on AGW" on the basis of the abstract alone went on to endorse AGW in the full paper, according to the self-ratings.
We also found that self-ratings were much more likely to have higher endorsement level rather than lower endorsement levels compared to our abstract ratings; four times more likely, in fact. 50% of self-ratings had higher endorsements than our corresponding abstract rating, while 12% had lower endorsement. Here is a histogram of the difference between our abstract rating and self-ratings. For example, if we rated the abstract as no-position (a value of 4) and the scientist rated the paper as implicit endorsement (a value of 3), then the difference was 1.
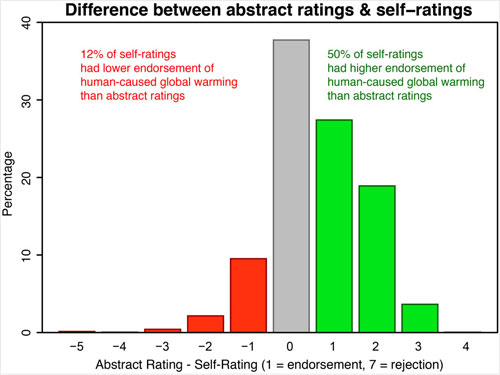
Figure 2: Histogram of Abstract Rating (expressed in percentages) minus Self-Rating. 1 = Explicit endorsement with quantification, 4 = No Expressed Position, 7 = Explicit rejection with quantification. Green bars are where self-ratings have a higher level of endorsement of AGW than the abstract rating. Red bars are where self-ratings have a lower level of endorsement of AGW than the abstract rating.
About the data
In accordance with the confidentiality conditions stipulated beforehand, we had to anonymise the self-rating data in order to protect the privacy of the scientists who filled out our survey. However, even with anonymised data, it's still possible to identify scientists due to many papers having a unique combination of year, abstract category and abstract endorsement level. Therefore, I've further anonymised the data by only including the Year, Abstract Endorsement Level and Self-Rating Endorsement Level. But even in this case, there were six self-rated papers with a unique combination of year and abstract endorsement level. So to maintain privacy, I removed those six papers from the sample of 2,142 papers.
In cases where we received more than one self-rating for a single paper (e.g., multiple authors rated the same paper), the self-rating was the average of the two ratings.









Interesting. There were three papers that were rated as "1" by Cook et al but were self-rated as "4" by the authors, and one paper (in 2006) that was rated as "1" by Cook et al that was self-rated as "7" by the author!
I know you've attempted to maintain the confidentiality of the authors but there were only six papers rated "1" in 2006 and I think I can make an educated guess which one was self-rated as "7" just by looking at the names of the authors and without even reading the papers involved.
There were 37 papers rated as "2" that were self-rated as "4" or higher (numerically speaking), and 148 papers rated as "3" that were self-rated as "4" or higher.
If we narrow it down to papers that were rated as endorsing the consensus but were self-rated as not endorsing the consensus (i.e. not neutral), then there was only one paper rated as a "1" (mentioned above), three papers rated as a "2", and eight papers rated as a "3". Not bad.
It's interesting to see the fractional numbers that indicated authors disagreeing on the self-rating of their papers. It's instructive to realise that self-ratings aren't a gold standard that cannot be wrong, demonstrated by the fact that different authors on the same paper rated it differently.
I find interesting the papers that flipped from endorsement to rejection, or vice-versa, in the process of self-rating.
Eleven went from endorsement to rejection, and 3 went from rejection to endorsement. Endorsement to rejection jumped an average of 3.4 points. Rejection to endorsement averaged 2.7 points.
But, overall, these are such a tiny fraction of the total number of papers as to be meaningless.
Here are the overall stats:
At least 3% of self ratings were inconsistent (ie, had at least two self ratings that disagreed). That is a much lower "error rate" than with the abstract ratings, which does not surprise given that the authors had acces to the full paper, not to mention knowledge of their intentions from which to assess their rating. That some errors still existed is probably due to ambiguity or misunderstanding of what is meant by "endorse". At least one author's self ratings disagreed with the abstract ratings due to misinterpretation of the meaning of "endorse" to mean "is evidence of". Another managed to disagree with the abstract rating by redefining "the consensus" to mean that approximately 100% of warming since 1900 has been due to anthropogenic factors, something few if any climate scientists would agree with and the IPCC has never claimed. Therefore it is wrong to assume that any instance of disagreement is due to an error by the abstract raters.
Tom,
At least 3% of self ratings were inconsistent (ie, had at least two self ratings that disagreed). That is a much lower "error rate" than with the abstract ratings, which does not surprise given that the authors had acces to the full paper, not to mention knowledge of their intentions from which to assess their rating.
Another two points:
1. Unlike the abstract ratings, all of which had at least two raters (and therefore an opportunity for inconsistency), my understanding is that at least some (perhaps the majority?) of the self-rated papers would have been self-rated by only one author. To compare rates of inconsistency we would need to know what percentage of self-rated papers that were rated by two or more authors gave inconsistent ratings (together with assurances that the authors didn't compare notes before responding).
2. We're inferring incosistent self-ratings by fractional averages, but of course if two self-ratings disagreed by two levels (for example), the average would be a whole number and we would mis-classify that as not inconsistent.
My direct reaction is how small the difference is between 1990 and now. How far would you need to go back to the time when there was still a reasonable controversy over climate change among climate scientists?
Just checking the WUWT site where the seven scientists actually had to say about the way their papers were assessed. The quest poster 'Andrew from Popular Technology' says 'To get to the truth, I emailed a sample of scientists whose papers were used in the study and asked them if the categorization by Cook et al. (2013) is an accurate representation of their paper.'
I am not sure of Andrew's statistical skills but seven is hardly a representative sample of scientists reviewed By Cook. But putting that aside, I read a few of the comments by these seven scientists and i was surprised to read they openly ADMIT their papers support AGW. The deception was the use of the word 'accurate'. They all went on to discuss the other effects that would account for tHe warming, but all stated there was something else was causing the increase in themperature and didn't deny it was humans who were responsible.
As an aside, when looking for 'Andrew from Popular Technology' post, I noticed many WUWT posts actually imply that the world is warming. But the gist of their posts is that it is 'good'. For instance, less Artic ice has caused the polar bear population to increase. it is obviously getting harder and harder to ignore the obvious.
Peeve @6... It's been asked many times of Andrew, who and how many scientists did he email? His response has been that he won't divulge that information because it's part of a piece of work that he's doing.
I've told him numerous times that his issues with Cook13 are addressed within the paper itself. But thus far my comments have fallen on deaf ears. It should be a little more difficult for him (and others) to ignore this obvious fact now that John has made this post.
Rob Honeycutt @7. It doesn't surprise me that you are not getting a response. I was enjoying commenting on WUWT, and to give them there credit, they allowed me to have my say - up to a point. i think it gave them an opportunity to attack me personnally (including threats of violence). In the end it must have been too embarrassing for them as they have banned me from ever commenting again.
Not only is Poptech's sample of 7 much smaller than our author self-rating sample of 1,200 (and over 2,100 papers), but his sample is biased toward "skeptics" who are more likely to reject the consensus, and also apparently more likely to pretend to endorse it in the abstract while claiming they rejected it in the full paper. Not exactly a compelling argument against our paper and conclusions.
Nichol@5
Try the An Interactive History of Climate Science gizmo.
I suggest about 1900 or 1901 and the Angstrom/Arrhenius disagreement.
dana @9, the claim that "skeptics" are "more likely to pretend to endorse it in the abstract while claiming they rejected it in the full paper" is not supported by Poptech' sample. One of Poptech's sample (Scaffeta) outrageously misrepresents the nature of the scientific consensus so that he can falsely claim an error in the abstract rating. Shaviv's abstract, however, concludes:
The increase over the 20th century was 0.7 K, so the paper attributes greater than 50% of warming to natural causes under an assumption the authors are willing to entertain. That indicates the paper should be rated (IMO) as at most a 5 (implicitly rejects), and certainly not, as it was actually rated, at 2 (Explicitly endorses).
In like manner, Idsos' abstract describes the impact of enhanced growth on the seasonal cycle in CO2 and should probably (and at most) have been rated neutral, but was actually rated 3 (implicitly endorses).
These two examples represent genuine mistakes. Of course, Poptech has only found two genuine errors from among a very large number of abstracts rated as endorsing the consensus. As always, he avoids mentioning the denominator.
Paul D @10, based on the interactive history, in the decade from 1961 to 1970, 20% of papers with a position where skeptical. While still a majority opinion, that suggests acceptance of AGW was hardly a consensus at that stage. Further, despite the evident overwhelming majority of papers endorsing the consensus from 1990, evidence from other sources suggest the consensus among scientists did not form until after 1995 and possibly not till after the Third Assessment report. It is very evident, however, that once the number of studies per decade started increasing, the consensus formed very rapidly.
Yeah Tom.I realised after posting the comment that i was going for the earliest point where there was a clash, rather than the most recent.
I have added some more graphs to the TCP datavisualisation that show the accumulation over the years since 1991. It's currently being tested.